AI Inference là gì
Trí tuệ nhân tạo đang xuất hiện trong hầu hết các công nghệ hiện đại, từ chatbot, công cụ tìm kiếm đến hệ thống nhận diện hình ảnh và xe tự hành. Tuy nhiên, để một mô hình AI có thể đưa ra câu trả lời, nhận diện đối tượng hoặc tạo nội dung mới, nó phải trải qua một giai đoạn quan trọng gọi là AI Inference. Vậy AI Inference là gì? Trong bài viết này, chúng ta sẽ tìm hiểu chi tiết AI Inference là gì, cách AI inference hoạt động, sự khác biệt giữa AI Training và AI Inference, các loại inference phổ biến, những chỉ số hiệu năng quan trọng cũng như các phương pháp tối ưu để giảm chi phí và tăng tốc độ xử lý của các hệ thống AI hiện đại.
1. AI Inference Là Gì?
AI Inference là quá trình mô hình trí tuệ nhân tạo sử dụng những gì đã học được trong giai đoạn huấn luyện để xử lý dữ liệu mới và đưa ra kết quả phù hợp. Nói một cách đơn giản, đây là bước mà AI bắt đầu “làm việc” sau khi đã hoàn thành quá trình Ai training học tập từ dữ liệu.
Khi người dùng nhập một câu hỏi vào chatbot, tải lên một bức ảnh để nhận diện hoặc tìm kiếm sản phẩm trên một trang thương mại điện tử, hệ thống AI sẽ phân tích dữ liệu đầu vào và đưa ra phản hồi gần như ngay lập tức. Toàn bộ quá trình đó chính là AI inference.
AI inference đóng vai trò trung tâm trong mọi ứng dụng AI hiện đại. Nếu quá trình huấn luyện giúp mô hình học hỏi kiến thức thì inference là giai đoạn biến kiến thức đó thành hành động thực tế. Chất lượng của AI inference ảnh hưởng trực tiếp đến tốc độ phản hồi, độ chính xác và trải nghiệm của người dùng.

2. AI Inference Hoạt Động Như Thế Nào?
Để tạo ra câu trả lời, dự đoán hoặc đề xuất phù hợp, AI phải trải qua một quy trình xử lý dữ liệu gọi là inference. Mặc dù các mô hình AI hiện đại có cấu trúc rất phức tạp, quá trình AI inference về cơ bản có thể được chia thành bốn bước chính, từ việc nhận dữ liệu đầu vào cho đến khi tạo ra kết quả cuối cùng.
Bước 1: Nhận dữ liệu đầu vào
Mọi quá trình AI inference đều bắt đầu bằng việc tiếp nhận dữ liệu từ người dùng hoặc hệ thống. Dữ liệu này có thể tồn tại dưới nhiều hình thức khác nhau như văn bản, hình ảnh, âm thanh hoặc video.
Ví dụ, khi bạn nhập một câu hỏi vào chatbot AI, tải lên một bức ảnh để nhận diện đối tượng hoặc sử dụng tính năng chuyển giọng nói thành văn bản, những thông tin đó sẽ trở thành dữ liệu đầu vào để mô hình AI xử lý.
Bước 2: Xử lý dữ liệu bằng mô hình AI
Sau khi nhận dữ liệu, hệ thống sẽ đưa thông tin vào mô hình AI đã được huấn luyện trước đó. Tùy thuộc vào mục đích sử dụng, AI có thể áp dụng nhiều loại mô hình khác nhau.
Các mô hình Neural Network thường được sử dụng cho nhiều tác vụ học máy phổ biến. CNN phù hợp với nhận diện và phân tích hình ảnh. Transformer là nền tảng của các mô hình ngôn ngữ hiện đại, trong khi các LLM như ChatGPT được thiết kế để hiểu và tạo nội dung bằng ngôn ngữ tự nhiên.
Ở giai đoạn này, mô hình sẽ phân tích dữ liệu đầu vào dựa trên những kiến thức đã học từ hàng triệu hoặc hàng tỷ mẫu dữ liệu trong quá trình huấn luyện.

Bước 3: Đánh giá các khả năng và tính toán kết quả
Sau khi phân tích dữ liệu, mô hình AI sẽ đánh giá nhiều khả năng khác nhau để tìm ra kết quả phù hợp nhất. Quá trình này dựa trên các trọng số đã được hình thành trong quá trình huấn luyện.
Ví dụ, khi bạn đặt câu hỏi cho chatbot, AI sẽ xem xét nhiều phương án trả lời khác nhau và lựa chọn những từ hoặc câu có khả năng phù hợp cao nhất. Trong nhận diện hình ảnh, hệ thống sẽ so sánh các đặc điểm của bức ảnh với dữ liệu đã học để xác định đối tượng xuất hiện trong ảnh là gì.
Đây là bước quyết định độ chính xác của toàn bộ quá trình AI inference.
Bước 4: Tạo kết quả đầu ra
Sau khi hoàn tất các phép tính, AI sẽ tạo ra kết quả và gửi lại cho người dùng hoặc hệ thống khác. Kết quả đầu ra có thể là một dự đoán, một nhãn phân loại, một đoạn văn bản, một bản dịch hoặc một quyết định tự động.
Chẳng hạn, chatbot sẽ trả lời câu hỏi của người dùng, hệ thống nhận diện khuôn mặt sẽ xác thực danh tính, còn công cụ đề xuất sản phẩm sẽ hiển thị những mặt hàng phù hợp với sở thích của từng khách hàng.

3. AI Inference Khác Gì So Với AI Training?
AI Training và AI Inference là hai giai đoạn quan trọng trong quá trình phát triển một hệ thống trí tuệ nhân tạo, nhưng chúng có mục đích và cách hoạt động hoàn toàn khác nhau. Hiểu rõ sự khác biệt này giúp bạn nắm được cách AI được xây dựng và cách nó vận hành trong thực tế.
AI Training là gì?
AI Training là giai đoạn mà mô hình AI được “học” từ dữ liệu. Trong quá trình này, hệ thống sẽ phân tích một lượng lớn dữ liệu đầu vào để tìm ra quy luật và mối quan hệ giữa các thông tin. Từ đó, mô hình dần điều chỉnh các tham số bên trong để đưa ra dự đoán chính xác hơn.
Có thể hiểu đơn giản, đây là bước “dạy” cho AI biết cách suy nghĩ và xử lý thông tin. Quá trình này thường yêu cầu nhiều thời gian, dữ liệu lớn và tài nguyên tính toán mạnh như GPU Server.
AI Inference là gì?
AI Inference là giai đoạn sử dụng mô hình đã được huấn luyện để xử lý dữ liệu mới và tạo ra kết quả. Khác với training, inference không làm thay đổi kiến thức của mô hình mà chỉ áp dụng những gì đã học để đưa ra dự đoán hoặc phản hồi.
Ví dụ, khi bạn nhập câu hỏi vào chatbot hoặc tải một hình ảnh lên hệ thống nhận diện, AI sẽ thực hiện inference để đưa ra câu trả lời hoặc kết quả phù hợp ngay lập tức.

Sự khác biệt giữa AI Training và AI Inference
AI Training và AI Inference khác nhau rõ rệt về mục tiêu, cách sử dụng dữ liệu, chi phí và yêu cầu tài nguyên. Training tập trung vào việc xây dựng và cải thiện mô hình nên thường sử dụng dữ liệu huấn luyện và cần nhiều thời gian xử lý. Ngược lại, inference sử dụng dữ liệu mới để dự đoán kết quả và thường diễn ra nhanh hơn nhiều.
Về chi phí, training thường tốn kém hơn vì cần hệ thống tính toán mạnh và thời gian dài để tối ưu mô hình. Trong khi đó, inference có chi phí thấp hơn và được tối ưu để phản hồi nhanh, đôi khi chỉ mất vài mili giây.
Ngoài ra, training thường chạy trên các hệ thống GPU mạnh để xử lý dữ liệu lớn, còn inference có thể chạy linh hoạt trên GPU, CPU hoặc các thiết bị chuyên dụng tùy vào nhu cầu. Điều này giúp AI có thể hoạt động hiệu quả cả trên máy chủ lẫn thiết bị cá nhân.
4. Các Loại AI Inference Phổ Biến
Trong thực tế, AI inference không chỉ có một kiểu hoạt động duy nhất mà được triển khai theo nhiều cách khác nhau tùy vào nhu cầu xử lý dữ liệu. Mỗi loại sẽ phù hợp với một mục đích riêng, từ xử lý hàng loạt đến phản hồi ngay lập tức trong thời gian thực.
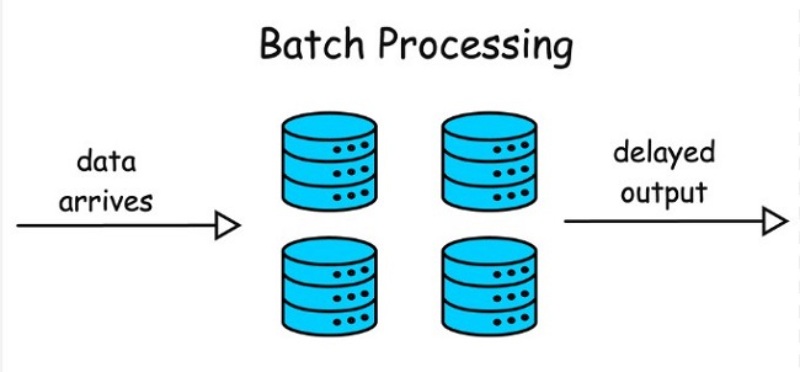
Batch Inference
Batch inference là cách xử lý dữ liệu theo từng nhóm lớn thay vì xử lý từng yêu cầu riêng lẻ. Hệ thống sẽ thu thập dữ liệu trong một khoảng thời gian nhất định, sau đó xử lý tất cả cùng lúc.
Cách làm này thường giúp tiết kiệm tài nguyên và tối ưu hiệu suất khi không cần phản hồi ngay lập tức. Tuy nhiên, nó không phù hợp với những ứng dụng yêu cầu tốc độ cao.
Batch inference thường được sử dụng trong các hệ thống phân tích dữ liệu lớn, báo cáo định kỳ hoặc xử lý dữ liệu người dùng theo ngày.
Real-Time Inference
Real-time inference là hình thức xử lý dữ liệu ngay khi hệ thống nhận được yêu cầu. Đây là kiểu inference phổ biến nhất trong các ứng dụng AI hiện đại vì mang lại trải nghiệm phản hồi gần như tức thì.
Loại này yêu cầu độ trễ rất thấp để đảm bảo người dùng nhận được kết quả nhanh nhất có thể. Ví dụ như chatbot trả lời câu hỏi, hệ thống gợi ý sản phẩm khi bạn đang mua sắm hoặc công cụ dịch ngôn ngữ trực tiếp.
Real-time inference đóng vai trò quan trọng trong những ứng dụng cần tương tác liên tục với người dùng.

Streaming Inference
Streaming inference xử lý dữ liệu liên tục theo dòng thay vì theo từng yêu cầu riêng lẻ. Điều này phù hợp với những hệ thống phải làm việc với dữ liệu được tạo ra liên tục theo thời gian.
Ví dụ phổ biến là phân tích video, xử lý dữ liệu từ cảm biến IoT hoặc theo dõi dữ liệu thời gian thực trong các hệ thống giám sát.
Cách hoạt động này giúp AI có thể phản ứng nhanh với những thay đổi nhỏ trong dữ liệu mà không cần chờ xử lý toàn bộ một lần.
Edge Inference
Edge inference là khi mô hình AI được chạy trực tiếp trên thiết bị cục bộ thay vì gửi dữ liệu về máy chủ trung tâm. Điều này giúp giảm độ trễ và tăng tính riêng tư cho người dùng.
Hình thức này thường được sử dụng trên smartphone, camera AI, thiết bị nhà thông minh hoặc các hệ thống xe tự hành.
Edge AI inference đặc biệt hữu ích trong những trường hợp cần phản hồi nhanh và không phụ thuộc vào kết nối internet ổn định.
5. AI Inference Cần Những Thành Phần Nào?
Để AI inference hoạt động ổn định và cho ra kết quả nhanh chóng, hệ thống cần sự kết hợp của nhiều thành phần khác nhau. Mỗi phần đóng một vai trò riêng, từ mô hình AI cho đến phần cứng và cách tối ưu xử lý dữ liệu.
Mô hình AI
Trung tâm của toàn bộ quá trình inference chính là mô hình AI đã được huấn luyện sẵn. Đây là nơi lưu trữ toàn bộ “kiến thức” mà AI học được từ dữ liệu trước đó.
Khi có dữ liệu mới, mô hình sẽ sử dụng những gì đã học để phân tích và đưa ra kết quả phù hợp. Chất lượng của mô hình ảnh hưởng trực tiếp đến độ chính xác của kết quả inference.

Inference Engine
Inference engine là lớp phần mềm giúp mô hình AI chạy hiệu quả hơn trên hệ thống thực tế. Nó đóng vai trò như một “bộ điều phối”, giúp tối ưu tốc độ xử lý và quản lý tài nguyên.
Một số inference engine phổ biến hiện nay gồm:
TensorRT, thường được dùng để tối ưu AI trên GPU NVIDIA
ONNX Runtime, hỗ trợ chạy mô hình trên nhiều nền tảng khác nhau
vLLM, tối ưu cho các mô hình ngôn ngữ lớn
TensorFlow Serving, dùng để triển khai mô hình AI trong môi trường sản xuất
Nhờ các công cụ này, quá trình inference trở nên nhanh hơn, ổn định hơn và dễ triển khai hơn trong thực tế.
Phần cứng
Phần cứng là yếu tố quyết định tốc độ và khả năng xử lý của AI inference. Tùy vào nhu cầu, hệ thống có thể sử dụng CPU, GPU hoặc các bộ xử lý chuyên dụng.
CPU Inference: CPU thường được dùng cho các tác vụ đơn giản hoặc hệ thống nhỏ. Ưu điểm là dễ triển khai và tiết kiệm chi phí, nhưng hiệu năng không cao khi xử lý mô hình lớn.
GPU Inference: GPU là lựa chọn phổ biến nhất hiện nay vì khả năng xử lý song song mạnh mẽ. Nó giúp tăng tốc đáng kể các mô hình AI phức tạp, đặc biệt là trong xử lý hình ảnh và ngôn ngữ.
NPU và AI Accelerator: Ngoài CPU và GPU, nhiều thiết bị hiện đại còn sử dụng NPU hoặc các bộ tăng tốc AI chuyên dụng. Những phần cứng này được thiết kế riêng cho tác vụ AI, giúp giảm tiêu thụ điện năng và tăng tốc độ xử lý trên thiết bị di động hoặc hệ thống nhúng.
Bộ nhớ và băng thông
Bên cạnh mô hình và phần cứng, bộ nhớ và băng thông cũng đóng vai trò quan trọng trong AI inference. Bộ nhớ giúp lưu trữ dữ liệu tạm thời trong quá trình xử lý, còn băng thông ảnh hưởng đến tốc độ truyền dữ liệu giữa các thành phần trong hệ thống.
Nếu bộ nhớ hoặc băng thông bị hạn chế, hiệu suất inference có thể giảm đáng kể, đặc biệt khi làm việc với các mô hình lớn hoặc dữ liệu phức tạp.

6. Các Chỉ Số Quan Trọng Trong AI Inference
Khi đánh giá hiệu suất của một hệ thống AI, đặc biệt là trong giai đoạn inference, có một số chỉ số quan trọng giúp bạn hiểu rõ tốc độ, độ ổn định và chi phí vận hành. Những chỉ số này ảnh hưởng trực tiếp đến trải nghiệm người dùng và khả năng mở rộng của hệ thống.
Latency (Độ trễ)
Latency là thời gian mà hệ thống cần để tạo ra một kết quả kể từ khi nhận dữ liệu đầu vào. Nói đơn giản, đây là khoảng thời gian bạn phải chờ để AI phản hồi.
Độ trễ càng thấp thì trải nghiệm càng mượt, đặc biệt quan trọng trong các ứng dụng như chatbot, dịch ngôn ngữ hoặc hệ thống gợi ý theo thời gian thực.
Throughput (Thông lượng)
Throughput thể hiện số lượng yêu cầu mà hệ thống có thể xử lý trong một khoảng thời gian nhất định. Chỉ số này càng cao thì hệ thống càng xử lý được nhiều người dùng cùng lúc.
Đây là yếu tố quan trọng với các nền tảng lớn có lượng truy cập cao như mạng xã hội, sàn thương mại điện tử hoặc dịch vụ AI công cộng.

Accuracy (Độ chính xác)
Accuracy phản ánh mức độ đúng đắn của kết quả mà mô hình AI đưa ra. Dù hệ thống có nhanh đến đâu, nếu kết quả không chính xác thì giá trị sử dụng cũng bị giảm đáng kể.
Trong nhiều trường hợp, cần cân bằng giữa tốc độ và độ chính xác để đạt hiệu quả tốt nhất.
Cost Per Inference (Chi phí cho mỗi lần xử lý)
Đây là chi phí mà hệ thống phải bỏ ra để xử lý một yêu cầu AI. Chi phí này bao gồm tài nguyên tính toán, bộ nhớ và hạ tầng máy chủ.
Khi hệ thống có hàng triệu lượt truy vấn mỗi ngày, việc tối ưu chi phí cho mỗi lần inference trở nên rất quan trọng để đảm bảo tính kinh tế.
Time To First Token (TTFT)
TTFT là thời gian từ khi người dùng gửi yêu cầu đến khi nhận được token đầu tiên từ mô hình AI. Chỉ số này đặc biệt quan trọng với các mô hình ngôn ngữ lớn vì nó ảnh hưởng trực tiếp đến cảm giác phản hồi ban đầu.
TTFT càng thấp thì người dùng càng cảm thấy hệ thống phản hồi nhanh hơn, ngay cả khi toàn bộ câu trả lời chưa hoàn tất.

Tokens Per Second (TPS)
TPS thể hiện số lượng token mà mô hình có thể tạo ra trong một giây. Đây là chỉ số quan trọng để đánh giá tốc độ sinh văn bản của các mô hình AI ngôn ngữ.
TPS cao giúp hệ thống tạo ra câu trả lời dài nhanh hơn và mượt hơn, đặc biệt hữu ích trong các ứng dụng như chatbot hoặc công cụ viết nội dung.
7. Cách Tối Ưu AI Inference
Khi mô hình AI ngày càng lớn và lượng người dùng ngày càng tăng, việc tối ưu AI inference trở thành yếu tố quan trọng để duy trì tốc độ phản hồi, giảm chi phí vận hành và nâng cao trải nghiệm người dùng. Thay vì chỉ nâng cấp phần cứng, nhiều doanh nghiệp còn áp dụng các kỹ thuật tối ưu mô hình và hệ thống để đạt hiệu quả tốt hơn.
Model Quantization
Model Quantization là phương pháp giảm độ chính xác của các phép tính trong mô hình từ định dạng dữ liệu lớn xuống định dạng nhỏ hơn. Điều này giúp giảm dung lượng mô hình và lượng bộ nhớ cần sử dụng trong quá trình inference.
Nhờ đó, hệ thống có thể xử lý nhanh hơn, tiêu thụ ít tài nguyên hơn và giảm chi phí hạ tầng. Đây là một trong những kỹ thuật phổ biến nhất để triển khai AI trên thiết bị di động hoặc các hệ thống có tài nguyên hạn chế.
Model Pruning
Model Pruning là quá trình loại bỏ những phần không thực sự cần thiết trong mô hình AI. Sau quá trình huấn luyện, nhiều tham số có rất ít tác động đến kết quả cuối cùng nhưng vẫn tiêu tốn tài nguyên xử lý.
Bằng cách loại bỏ những thành phần dư thừa này, mô hình trở nên gọn nhẹ hơn, giúp tăng tốc độ inference mà vẫn duy trì độ chính xác ở mức chấp nhận được.

Distillation
Distillation là kỹ thuật chuyển kiến thức từ một mô hình lớn sang một mô hình nhỏ hơn. Mô hình lớn đóng vai trò như “giáo viên”, còn mô hình nhỏ là “học sinh”.
Sau quá trình học lại, mô hình nhỏ có thể đạt hiệu suất gần tương đương mô hình gốc nhưng yêu cầu ít tài nguyên hơn đáng kể. Đây là giải pháp được nhiều công ty sử dụng khi muốn triển khai AI trên quy mô lớn hoặc trên các thiết bị cá nhân.
Caching
Caching là phương pháp lưu lại các kết quả đã được xử lý trước đó để tái sử dụng khi có yêu cầu tương tự.
Ví dụ, nếu nhiều người dùng đặt cùng một câu hỏi hoặc yêu cầu một nội dung giống nhau, hệ thống có thể trả về kết quả đã lưu thay vì thực hiện toàn bộ quá trình inference từ đầu. Điều này giúp giảm tải cho máy chủ và cải thiện tốc độ phản hồi.
Dynamic Batching
Dynamic Batching là kỹ thuật gom nhiều yêu cầu inference thành một nhóm để xử lý cùng lúc.
Thay vì xử lý từng yêu cầu riêng lẻ, hệ thống sẽ kết hợp nhiều truy vấn và tận dụng tối đa sức mạnh của phần cứng. Cách tiếp cận này giúp tăng thông lượng, giảm chi phí vận hành và cải thiện hiệu suất tổng thể của hệ thống AI.
GPU Optimization
GPU Optimization là tập hợp các phương pháp tối ưu việc sử dụng GPU trong quá trình inference. Điều này bao gồm việc phân bổ tài nguyên hợp lý, tận dụng các thư viện tăng tốc chuyên dụng và tối ưu luồng xử lý dữ liệu.
Khi GPU được khai thác hiệu quả, hệ thống có thể xử lý nhiều yêu cầu hơn trong cùng một khoảng thời gian, đồng thời giảm độ trễ và chi phí vận hành.
8. AI Inference Được Ứng Dụng Ở Đâu?
AI inference là nền tảng giúp các hệ thống trí tuệ nhân tạo hoạt động trong thực tế. Mỗi khi AI đưa ra câu trả lời, nhận diện hình ảnh hoặc đề xuất nội dung phù hợp, quá trình inference đang diễn ra phía sau. Hiện nay, công nghệ này được ứng dụng trong nhiều lĩnh vực khác nhau, từ đời sống hàng ngày đến các ngành công nghiệp quy mô lớn.
Chatbot AI
Chatbot là một trong những ứng dụng phổ biến nhất của AI inference. Khi người dùng đặt câu hỏi, hệ thống sẽ phân tích nội dung, hiểu ý định và tạo ra câu trả lời phù hợp trong thời gian rất ngắn.
Các trợ lý AI hiện đại có thể hỗ trợ chăm sóc khách hàng, giải đáp thông tin, hỗ trợ học tập và tạo nội dung tự động. Chất lượng của AI inference ảnh hưởng trực tiếp đến tốc độ và độ chính xác của các cuộc hội thoại.
Công Cụ Tìm Kiếm
Các công cụ tìm kiếm sử dụng AI inference để hiểu truy vấn của người dùng và hiển thị kết quả phù hợp nhất. Thay vì chỉ dựa vào từ khóa, AI còn có thể phân tích ngữ cảnh, mục đích tìm kiếm và hành vi người dùng để cải thiện độ liên quan của kết quả.
Nhờ đó, người dùng có thể tìm thấy thông tin cần thiết nhanh hơn và chính xác hơn.
Hệ Thống Đề Xuất
Các nền tảng thương mại điện tử, xem phim trực tuyến và mạng xã hội đều sử dụng AI inference để đề xuất nội dung phù hợp cho từng người dùng.
Hệ thống sẽ phân tích lịch sử tìm kiếm, thói quen sử dụng và sở thích cá nhân để dự đoán những sản phẩm, video hoặc bài viết mà người dùng có khả năng quan tâm. Đây là một trong những ứng dụng mang lại giá trị kinh doanh lớn nhất của AI hiện nay.
Xe Tự Lái
Trong lĩnh vực giao thông thông minh, AI inference giúp xe tự lái nhận biết môi trường xung quanh và đưa ra quyết định trong thời gian thực.
Hệ thống có thể phân tích dữ liệu từ camera, radar và cảm biến để phát hiện người đi bộ, phương tiện khác, biển báo giao thông và các vật cản trên đường. Mọi quyết định như tăng tốc, giảm tốc hoặc chuyển hướng đều phụ thuộc vào khả năng inference của AI.
Y Tế
Ngành y tế đang ứng dụng AI inference để hỗ trợ chẩn đoán bệnh, phân tích hình ảnh y khoa và đánh giá nguy cơ sức khỏe.
Ví dụ, AI có thể phát hiện những dấu hiệu bất thường trong ảnh chụp X-quang, MRI hoặc CT Scan nhanh hơn so với phương pháp thủ công. Điều này giúp bác sĩ có thêm công cụ hỗ trợ trong quá trình đưa ra quyết định điều trị.
Tài Chính
Trong lĩnh vực tài chính, AI inference được sử dụng để phát hiện gian lận, đánh giá rủi ro tín dụng và hỗ trợ đầu tư.
Các hệ thống AI có thể phân tích hàng triệu giao dịch trong thời gian ngắn để phát hiện những hoạt động bất thường. Đồng thời, AI cũng giúp các tổ chức tài chính đánh giá khả năng thanh toán của khách hàng và đưa ra các đề xuất phù hợp.
Sản Xuất Thông Minh
Các nhà máy hiện đại sử dụng AI inference để theo dõi dây chuyền sản xuất, phát hiện lỗi sản phẩm và tối ưu quy trình vận hành.
Thông qua dữ liệu từ cảm biến và camera, AI có thể nhận biết các vấn đề phát sinh gần như ngay lập tức, giúp doanh nghiệp giảm chi phí, hạn chế sai sót và nâng cao hiệu quả sản xuất.
Camera Giám Sát AI
Camera giám sát tích hợp AI đang ngày càng phổ biến trong doanh nghiệp, trung tâm thương mại và khu dân cư.
Nhờ AI inference, hệ thống có thể nhận diện khuôn mặt, phát hiện hành vi bất thường, đếm số lượng người hoặc cảnh báo khi xuất hiện các tình huống nguy hiểm. Điều này giúp nâng cao hiệu quả giám sát và giảm sự phụ thuộc vào việc theo dõi thủ công.
9. Những Thách Thức Của AI Inference
Mặc dù AI inference đóng vai trò quan trọng trong các ứng dụng trí tuệ nhân tạo hiện đại, việc triển khai và vận hành các hệ thống này không hề đơn giản. Khi mô hình AI ngày càng lớn và lượng người dùng tăng liên tục, doanh nghiệp phải đối mặt với nhiều thách thức liên quan đến chi phí, hiệu suất và khả năng vận hành lâu dài.
Chi Phí Hạ Tầng Cao
Một trong những thách thức lớn nhất của AI inference là chi phí hạ tầng. Các mô hình AI hiện đại, đặc biệt là mô hình ngôn ngữ lớn, thường yêu cầu máy chủ mạnh cùng hệ thống GPU có hiệu năng cao để xử lý dữ liệu nhanh chóng.
Ngoài chi phí đầu tư phần cứng, doanh nghiệp còn phải chi trả cho lưu trữ dữ liệu, băng thông mạng, bảo trì hệ thống và các dịch vụ điện toán đám mây. Khi số lượng yêu cầu tăng lên, tổng chi phí vận hành cũng có thể tăng rất nhanh nếu không có chiến lược tối ưu phù hợp.
Độ Trễ Khi Phục Vụ Lượng Truy Cập Lớn
Người dùng ngày nay mong muốn nhận được phản hồi gần như ngay lập tức từ các ứng dụng AI. Tuy nhiên, khi hàng nghìn hoặc hàng triệu yêu cầu được gửi đến cùng lúc, hệ thống có thể gặp tình trạng quá tải và làm tăng thời gian phản hồi.
Độ trễ cao không chỉ ảnh hưởng đến trải nghiệm người dùng mà còn làm giảm hiệu quả của các ứng dụng cần xử lý theo thời gian thực như chatbot, trợ lý ảo, dịch ngôn ngữ hoặc hệ thống hỗ trợ khách hàng.
Tiêu Thụ Điện Năng
Các trung tâm dữ liệu phục vụ AI inference thường tiêu thụ lượng điện năng rất lớn. Những mô hình có hàng tỷ tham số cần nhiều tài nguyên tính toán để tạo ra kết quả, đặc biệt khi phải phục vụ hàng triệu người dùng mỗi ngày.
Chi phí điện năng ngày càng trở thành một vấn đề đáng quan tâm đối với các doanh nghiệp triển khai AI ở quy mô lớn. Đây cũng là lý do nhiều công ty đang tập trung vào các giải pháp tối ưu mô hình và sử dụng phần cứng tiết kiệm năng lượng hơn.
Bảo Mật Dữ Liệu
Trong nhiều trường hợp, AI inference phải xử lý các dữ liệu quan trọng như thông tin khách hàng, dữ liệu tài chính hoặc hồ sơ y tế. Điều này đặt ra yêu cầu rất cao về bảo mật và quyền riêng tư.
Nếu hệ thống không được bảo vệ tốt, dữ liệu có thể bị truy cập trái phép hoặc bị rò rỉ trong quá trình xử lý. Vì vậy, các doanh nghiệp cần áp dụng các biện pháp bảo mật phù hợp để đảm bảo dữ liệu luôn được lưu trữ và xử lý an toàn.
Khả Năng Mở Rộng Hệ Thống
Khi số lượng người dùng tăng lên, hệ thống AI cần có khả năng mở rộng để duy trì hiệu suất ổn định. Đây là một thách thức lớn vì việc mở rộng không chỉ liên quan đến phần cứng mà còn ảnh hưởng đến kiến trúc hệ thống, băng thông mạng và khả năng phân phối tài nguyên.
Nếu không được thiết kế tốt ngay từ đầu, hệ thống có thể gặp tình trạng nghẽn tài nguyên, tăng chi phí vận hành hoặc suy giảm chất lượng dịch vụ khi lưu lượng truy cập tăng mạnh.
10. Xu Hướng AI Inference Trong Tương Lai
Khi trí tuệ nhân tạo ngày càng được ứng dụng rộng rãi, AI inference cũng đang phát triển nhanh chóng để đáp ứng nhu cầu về tốc độ, chi phí và khả năng xử lý ngày càng cao. Trong những năm tới, nhiều công nghệ mới sẽ giúp AI hoạt động hiệu quả hơn, phản hồi nhanh hơn và xuất hiện trên nhiều thiết bị hơn bao giờ hết.
Edge AI Phát Triển Mạnh
Một trong những xu hướng nổi bật nhất là sự phát triển của Edge AI. Thay vì gửi dữ liệu lên máy chủ hoặc nền tảng đám mây để xử lý, AI sẽ thực hiện inference trực tiếp trên thiết bị như điện thoại, camera, thiết bị đeo thông minh hoặc hệ thống IoT.
Cách tiếp cận này giúp giảm độ trễ, tăng tốc độ phản hồi và hạn chế việc truyền dữ liệu qua internet. Đồng thời, người dùng cũng được hưởng lợi từ khả năng bảo mật và quyền riêng tư tốt hơn vì dữ liệu được xử lý ngay trên thiết bị.
AI Accelerator Chuyên Dụng
Nhu cầu xử lý AI ngày càng lớn đang thúc đẩy sự phát triển của các bộ xử lý chuyên dụng dành riêng cho AI inference. Thay vì phụ thuộc hoàn toàn vào CPU hoặc GPU truyền thống, nhiều nhà sản xuất đang phát triển các AI Accelerator được thiết kế để tối ưu cho các tác vụ trí tuệ nhân tạo.
Những bộ xử lý này có thể mang lại hiệu năng cao hơn, tiêu thụ ít điện năng hơn và giúp giảm đáng kể chi phí vận hành. Đây sẽ là nền tảng quan trọng cho các hệ thống AI quy mô lớn trong tương lai.
Inference Cho Mô Hình Đa Phương Thức
Các mô hình AI hiện đại không còn chỉ xử lý văn bản hoặc hình ảnh riêng lẻ. Ngày càng nhiều hệ thống có khả năng hiểu và xử lý đồng thời nhiều loại dữ liệu khác nhau như văn bản, hình ảnh, âm thanh và video.
Điều này tạo ra nhu cầu về các hệ thống inference mạnh mẽ hơn để có thể xử lý lượng dữ liệu phức tạp trong thời gian ngắn. Trong tương lai, các mô hình đa phương thức sẽ trở thành tiêu chuẩn trong nhiều ứng dụng AI từ trợ lý ảo đến công cụ sáng tạo nội dung.
AI Chạy Trực Tiếp Trên Thiết Bị Cá Nhân
Sự cải tiến của phần cứng đang mở ra khả năng chạy các mô hình AI ngay trên laptop, smartphone và các thiết bị cá nhân khác. Người dùng sẽ không cần phụ thuộc hoàn toàn vào các dịch vụ đám mây để sử dụng các tính năng AI.
Xu hướng này giúp giảm chi phí sử dụng dịch vụ trực tuyến, tăng tốc độ phản hồi và cho phép AI hoạt động ngay cả khi không có kết nối internet. Đây cũng là lý do ngày càng nhiều hãng công nghệ đầu tư vào các tính năng AI tích hợp trực tiếp trên thiết bị.
Inference Tối Ưu Cho Agentic AI
Agentic AI là thế hệ AI có khả năng tự lập kế hoạch, đưa ra quyết định và thực hiện nhiều bước hành động để hoàn thành một mục tiêu cụ thể. Khác với chatbot truyền thống chỉ phản hồi từng câu hỏi, Agentic AI có thể xử lý các nhiệm vụ phức tạp và phối hợp nhiều công cụ khác nhau.
Để hỗ trợ những hệ thống này, AI inference cần được tối ưu hơn về tốc độ, khả năng quản lý tài nguyên và xử lý nhiều yêu cầu cùng lúc. Đây được xem là một trong những hướng phát triển quan trọng của ngành AI trong những năm tới.
Kết Luận
AI Inference là quá trình giúp mô hình trí tuệ nhân tạo biến những kiến thức đã học thành các dự đoán, quyết định hoặc phản hồi thực tế. Đây là giai đoạn cốt lõi đứng sau mọi ứng dụng AI hiện đại, từ chatbot, công cụ tìm kiếm, hệ thống đề xuất sản phẩm cho đến nhận diện hình ảnh và xe tự hành. Việc hiểu rõ AI Inference là gì không chỉ giúp bạn nắm được cách AI hoạt động mà còn giúp doanh nghiệp đưa ra những quyết định phù hợp khi triển khai các giải pháp trí tuệ nhân tạo.
Tin tức khác

GPU as a Service (GPUaaS)

AI factory là gì

AI Cluster là gì
Batch Processing là gì

AI workflow là gì

